Tracing, evaluation, and error analysis for agents
Chat with AI to debug agent traces, create smart monitoring columns, and build out tailored evaluations.





Find and fix AI issues
Chat with your traces
Agent trace data is huge and hard to read. Gentrace Chat, inspired by Cursor, has full context of what's on your screen, allowing you to quickly answer questions like:
Generate custom monitoring code with AI
Never miss critical AI issues
Get notified instantly when issues arise and receive regular quality summaries to track your AI performance
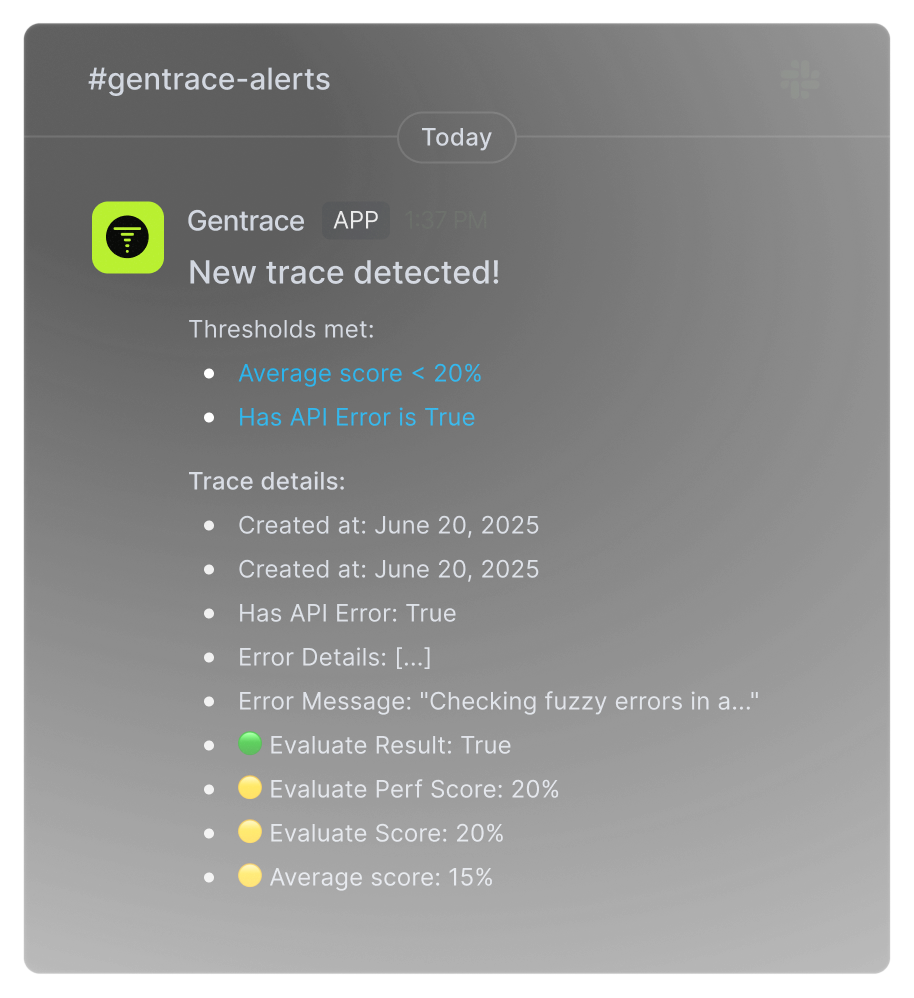


Best practice monitoring with easy install
Easy install
Gentrace provides a minimal tracing SDK for quickly tracing your AI agent.
1import { init, interaction } from 'gentrace';
2
3init()
4
5const haiku = interaction(‘haiku’, () => {
6 return myLlm.invoke('make a haiku');
7})
8
9haiku();1GENTRACE_API_KEY=YOUR_API_KEY npx tsx index.tsGenerate API Key
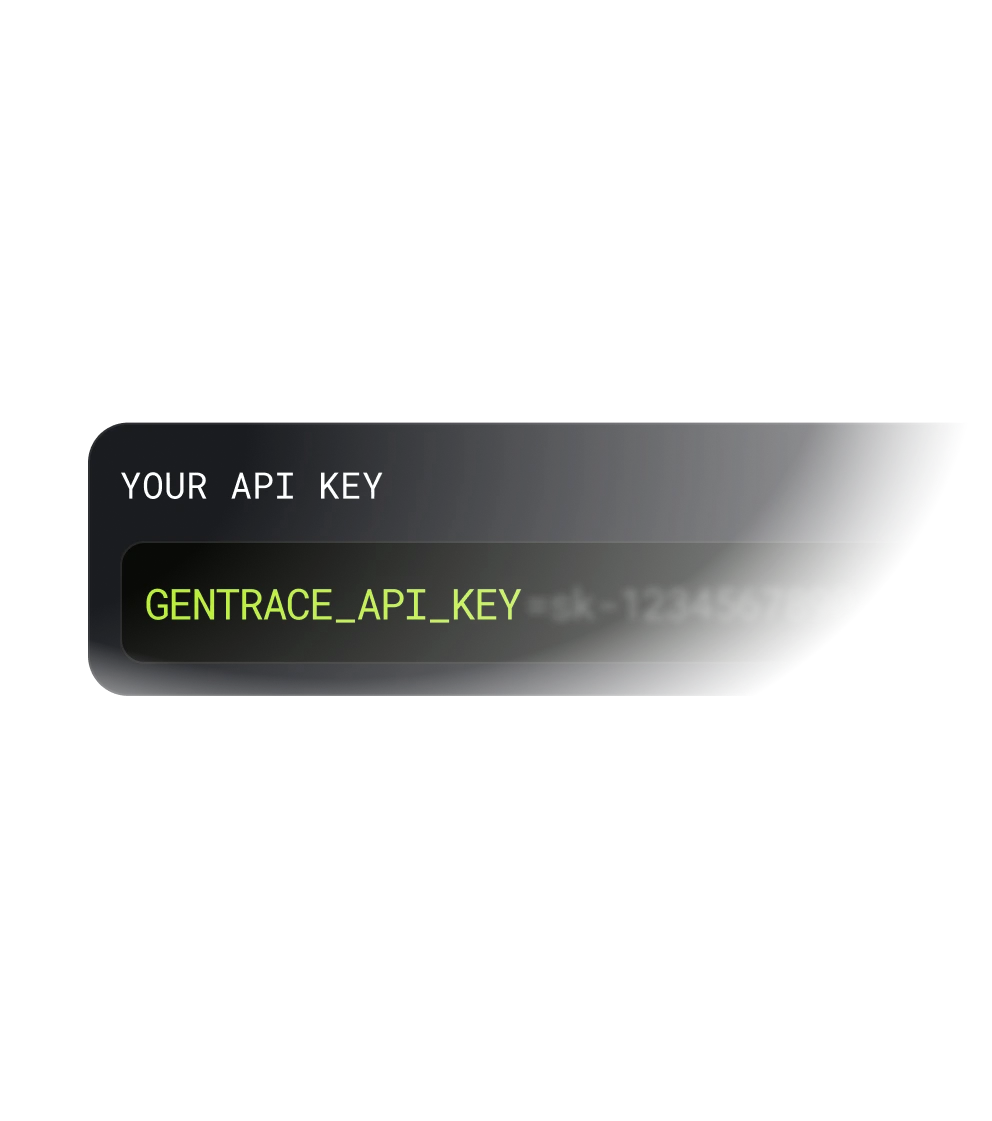
Click to generate your unique API key.
Authenticate
Install the Gentrace SDK using npm.
Learn more about how to instrument LLM calls.
Initialize in Your Project
Use the following TypeScript code to initialize the SDK and define an LLM interaction.
Widespread compatibility








Built on open standards
Built on OpenTelemetry, the industry standard for observability, ensuring compatibility with any monitoring stack
Get started1# This wraps the function in an OpenTelemetry span
2# for submission to Gentrace.
3@interaction(name="simple_example")
4def my_agent(input: str, user_id: str) -> Dict[str, str]:
5 # You can access the current span using the OpenTelemetry API.
6 span = get_current_span()
7 span.set_attribute("user_id", user_id)
8 return my_agent_inner(input)

Capture regressions before they go live
Powerful evals, lightweight setup
Begin with lightweight evaluations that deliver immediate insights, then expand to comprehensive testing workflows as your requirements evolve.
Get started tracing your agent1// Run a "unit test" evaluation
2await evalOnce('rs-in-strawberry', async () => {
3 const response = await openai.chat.completions.create({
4 model: 'gpt-o4-mini',
5 messages: [{ role: 'user', content: 'How many rs in
6 strawberry? Return only the number.'}],
7 });
8 const output = response.choices[0].message.content;
9 if (output !== '3') {
10 throw new Error('Output is not 3: ${output}’ );
11 }
12});1// Run a "dataset" evaluation
2await evalDataset({
3 data: async () => (await testCases.list()).data,
4 inputSchema: z.object({ query: z.string() }),
5 interaction: async (case) => {
6 return await runMyAgent(case.inputs.query);
7 }
8});Turn experiments into insights
Flexible dataset management
Store test data in Gentrace or your codebase, organize it efficiently with built-in management tools, and write experiments directly in code for maximum flexibility.
Learn more about datasets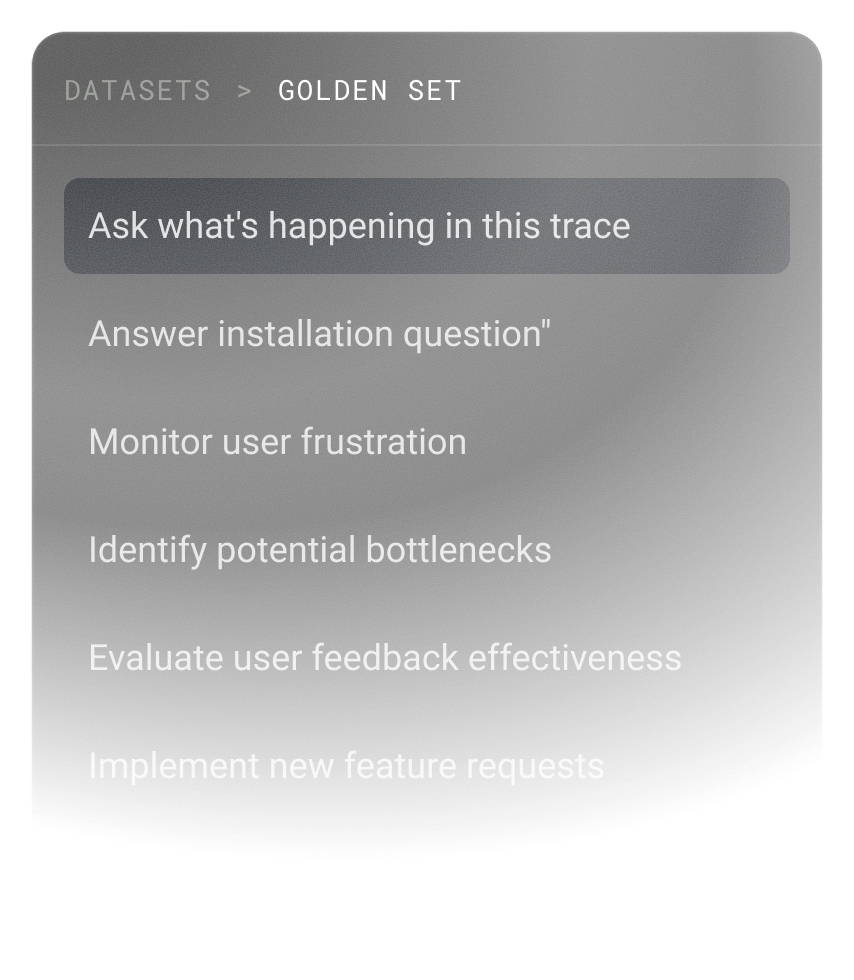

Gentrace was the right product for us because it allowed us to implement our own custom evaluations, which was crucial for our unique use cases. It's dramatically improved our ability to predict the impact of even small changes in our LLM implementations.


access control




